
Что такое репликация данных
Репликация — одна из техник масштабирования баз данных.
Состоит эта техника в том, что данные с одного сервера базы данных постоянно копируются (реплицируются) на один или несколько других (называемые репликами). Для приложения появляется возможность использовать не один сервер для обработки всех запросов, а несколько. Таким образом появляется возможность распределить нагрузку с одного сервера на несколько.
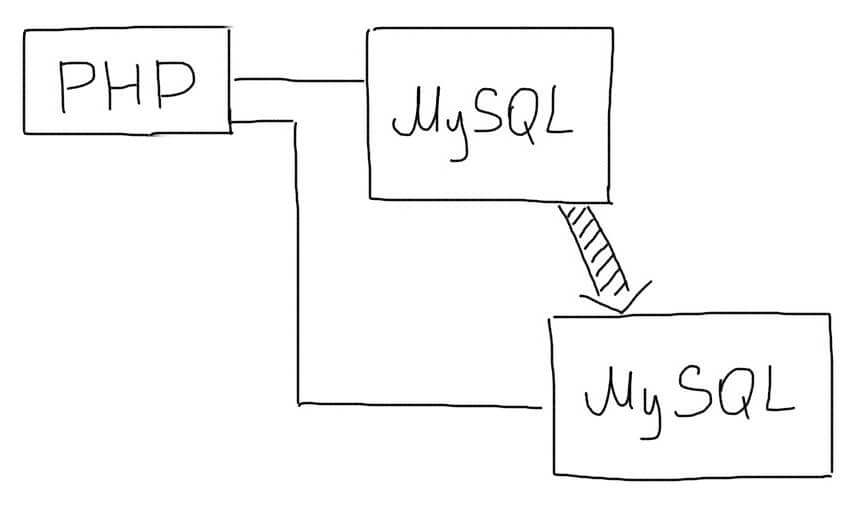
Существует два основных подхода при работе с репликацией данных:
Master-Slave репликация
В этом подходе выделяется один основной сервер базы данных, который называется Master. На нем происходят все изменения в данных (любые запросы INSERT/UPDATE/DELETE).
Slave сервер постоянно копирует все изменения с Master. С приложения на Slave-сервер отправляются запросы чтения данных (запросы SELECT). Таким образом Master-сервер отвечает за изменения данных, а Slave за чтение.
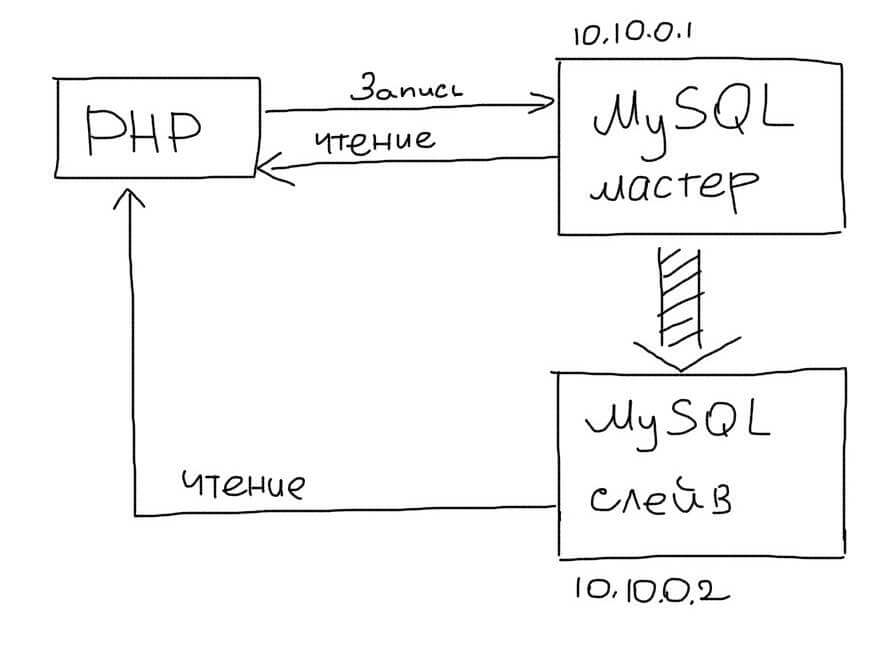
Читайте как настроить Master-Slave репликацию на MySQL
В приложении нужно использовать два соединения — одно для Master, второе — для Slave:
(Используем два соединения — для Master и Slave — для записи и чтения соответственно)
1 | <? |
Несколько Slave серверов
Преимущество этого типа репликации в том, что мы можем использовать более одного Slave сервера. Обычно следует использовать не более 20 Slave серверов при работе с одним Master.
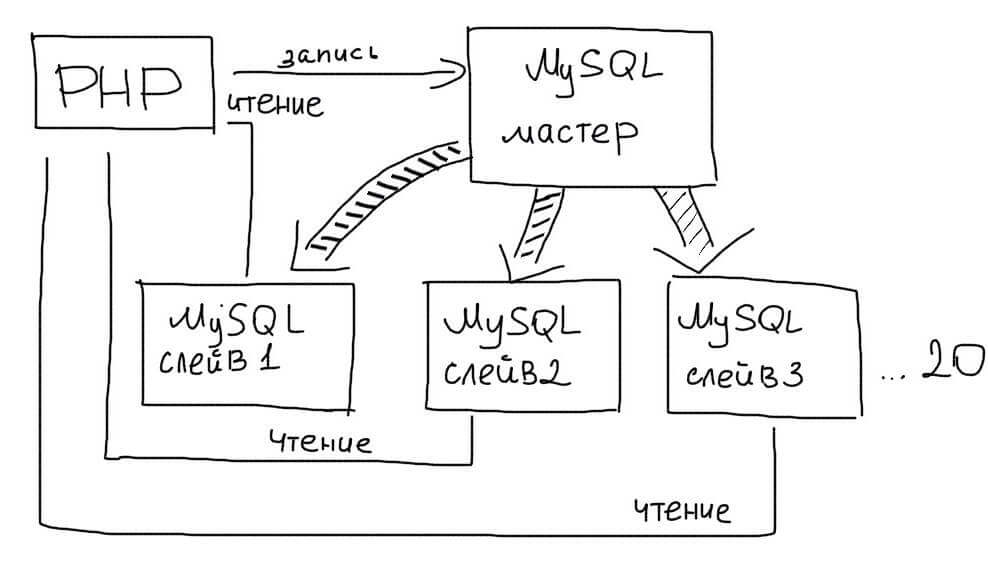
Тогда приложение выбирает случайным образом один из Slave серверов для обработки запросов:
1 | <? |
Задержка репликации
Асинхронность репликации означает, что данные на Slave могут появиться с небольшой задержкой. Поэтому, в последовательных операциях необходимо использовать чтение с Master, чтобы получить актуальные данные:
(При обращении к изменяемым данным, необходимо использовать Master-соединение)
1 | <? |
Выход из строя
При выходе из строя Slave, достаточно просто переключить все приложение на работу с Master. После этого восстановить репликацию на Slave и снова его запустить.
Если выходит из строя Master, нужно переключить все операции (и чтения и записи) на Slave. Таким образом он станет новым Master. После восстановления старого Master, настроить на нем реплику, и он станет новым Slave.
Резервирование
Намного чаще репликацию Master-Slave используют не для масштабирования, а для резервирования. В этом случае, Master сервер обрабатывает все запросы от приложения. Slave сервер работает в пассивном режиме. Но в случае выхода из строя Master, все операции переключаются на Slave.
Master-Master репликация
В этой схеме, любой из серверов может использоваться как для чтения так и для записи:
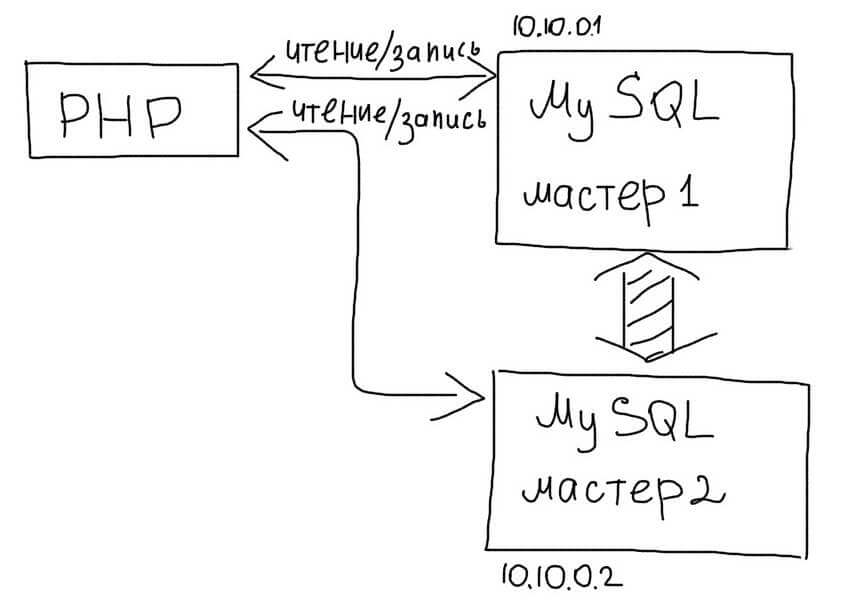
Читайте как настроить Master-Master репликацию на MySQL
При использовании такого типа репликации достаточно выбирать случайное соединение из доступных Master серверов:
(Выбор случайного Master для обработки соединений)
1 | <? |
Выход из строя
Вероятные поломки делают Master-Master репликацию непривлекательной. Выход из строя одного из серверов практически всегда приводит к потере каких-то данных. Последующее восстановление также сильно затрудняется необходимостью ручного анализа данных, которые успели либо не успели скопироваться.
Используйте Master-Master репликацию только в крайнем случае. Вместо нее лучше пользоваться техникой “ручной” репликации, описанной ниже.
Асинхронность репликации
В MySQL репликация работает в асинхронном режиме. Это значит, что приложение не знает, как быстро данные появятся на Slave.
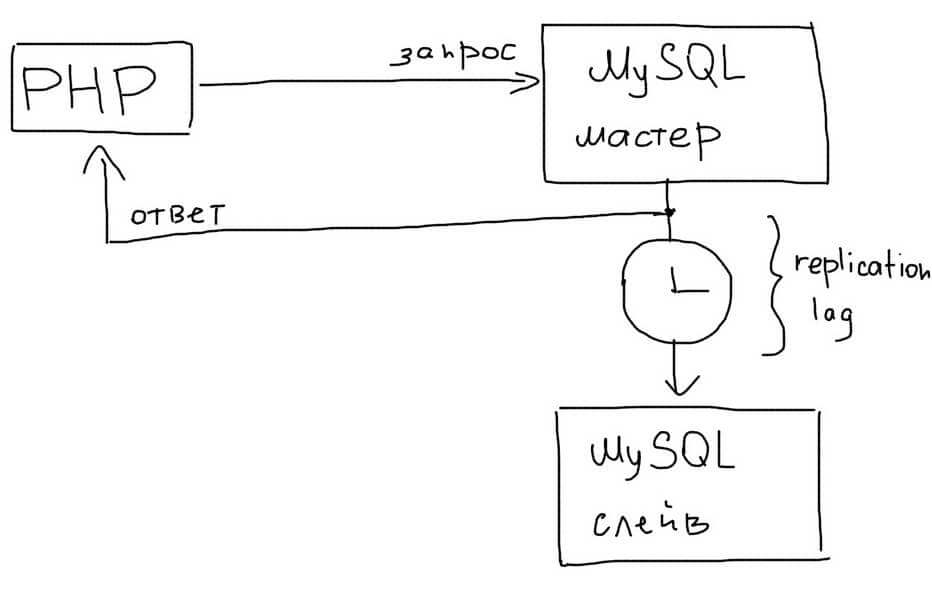
Задержка в репликации (replication lag) может быть как очень маленькой, так и очень большой. Обычно рост задержки говорит о том, что сервера не справляются с текущей нагрузкой и их необходимо масштабировать дальше, например техниками горизонтального и вертикального шардинга.
Синхронный режим
Синхронный режим репликации позволит гарантировать копирование данных на Slave.
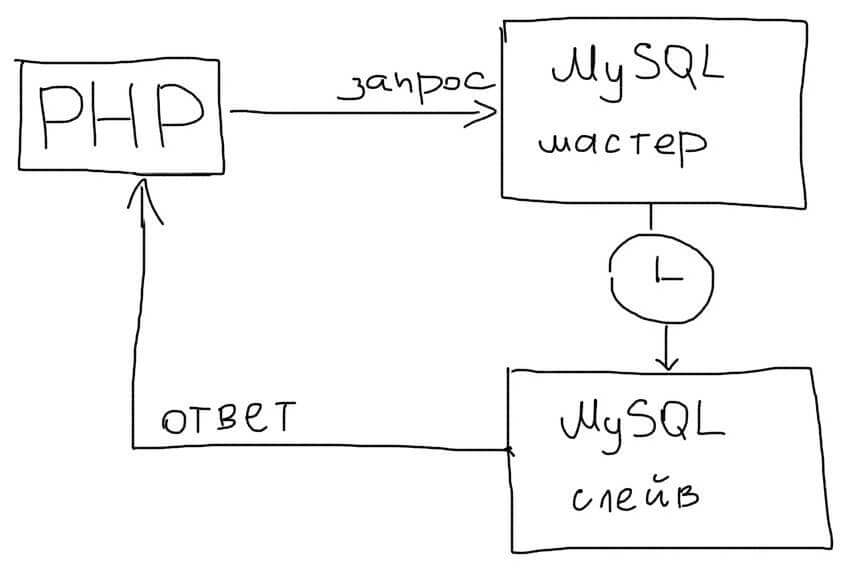
Это упростит работу в приложении, т.к. все операции чтения можно будет всегда отправлять на Slave. Однако это может значительно уменьшить скорость работы MySQL. Синхронный режим не следует использовать в Web приложениях.
“Ручная” репликация
Следует помнить, что репликация — это не технология, а методика. Встроенные механизмы репликации могут принести ненужные усложнения либо не иметь какой-то нужной функции. Некоторые технологии вообще не имеют встроенной репликации.
В таких случаях, следует использовать самостоятельную реализацию репликации. В самом простом случае, приложение будет дублировать все запросы сразу на несколько серверов базы данных:
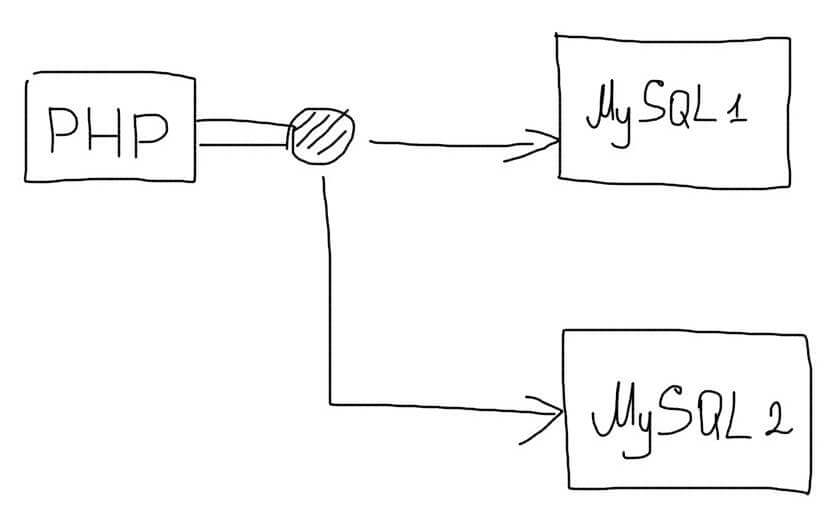
При записи данных, все запросы будут отправляться на несколько серверов. Зато операции чтения можно будет отправлять на любой сервер. Нагрузка при этом будет распределяться по всем доступным серверам:
(Все операции изменения данных происходят на нескольких серверах, а чтения — на одном случайном)
1 | <? |
Это позволит использовать преимущества репликации даже если сама технология ее не поддерживает.
Выход из строя
При поломке одного из серверов в такой схеме необходимо сделать следующее:
- Исключить сервер из списка используемых.
- Настроить репликацию Master-Slave на новом сервере, используя один из рабочих серверов в качестве Master.
- Когда все данные репликации будут синхронизированы, включить сервер обратно в список используемых и остановить репликацию.
Самое важное
Репликация используется в большей мере для резервирования баз данных и в меньшей для масштабирования. Master-Slave репликация удобна для распределения запросов чтения по нескольким серверам. Подход ручной репликации позволит использовать преимущества репликации для технологий, которые ее не поддерживают. Зачастую репликация используется вместе с шардингом при решении вопросов масштабирования.