
Горизонтальный шардинг MySQL
Примеры настройки горизонтального шардинга в приложении
Так или иначе возникает ситуация, когда на сервере базы данных со временем приходится работать с огромными таблицами.
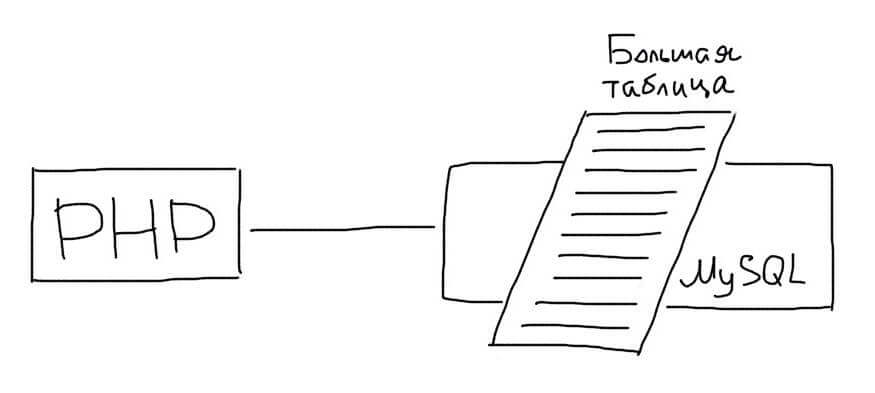
В таких случаях можно использовать специальную технику горизонтального шардинга. При этом большая таблица разбивается на несколько частей. Каждая часть таблицы помещается на отдельный сервер.
Подготовка
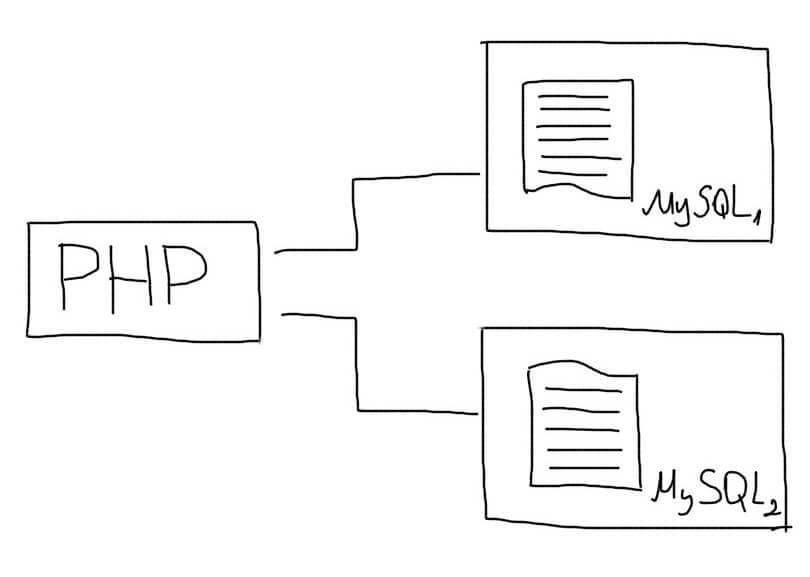
Для внедрения горизонтального шардинга необходимо подготовить несколько одинаковых серверов базы данных. На каждом из них должна быть создана структура выбранной таблицы. Работа по распределению данных ложится на само приложение.
Распределение данных
Прежде всего, данные в больших таблицах необходимо как-то разделять между серверами. Для этого нужно определить условие разделения. Представим, что мы разделяем таблицу photos, которая хранит фотки пользователей. Она имеет такую структуру:
- id
- user_id
- date
- photo
Мы могли бы использовать колонку user_id для разделения данных в этой таблице. Тогда все фотографии для четных пользователей мы могли бы сохранять на один сервер.
А для нечетных — на другой:
(выбираем разные соединения — для четных и нечетных значений $user_id)
1 | <? |
При выборке данных для конкретного пользователя нам также нужно определять соответствующее соединение:
(Для любых обращений к таблице photos необходимо выбирать нужное соединение)
1 | <? |
Разделение на n серверов
Остаток от деления хорошо подходит для равномерного распределения записей по любому количеству серверов. Так, если у нас 7 шардов, мы будем использовать остаток от деления на 7:
(остаток от деления позволяет удобно разделить данные между серверами)
1 | <? |
Если серверов будет 50, будем использовать остаток от 50 и т.п. Таким образом мы можем равномерно разделять любые таблицы по условию остатка от деления значения какой-то колонки. Для этого типа деления хорошо подходят таблицы, у которых есть связь с родительским объектом:
- фотки пользователей, делим по
user_id - сообщения пользователей, делим по
user_id - комментарии статьи, делим по
article_id - товары в категории, делим по
category_id
…
Словарь
Иногда нет возможности поделить данные по какой-то цифровой колонке. Допустим, у нас есть очень большая таблица с новостями, которую мы хотим разделить на несколько серверов (шардов):
- id
- title
- body
В этом случае следует использовать словарь. Это еще одна таблица, в которой будет указана связь между ID новости и номером шарда. В момент добавления новости мы будем выбирать случайный шард и записывать его номер в словарь:
(Соединение $dict_con используется для словаря)
1 | <? |
Тогда для чтения данных какой-то новости необходимо будет сначала получить номер шарда из словаря:
(Получаем номер шарда, а затем данные новости)
1 | <? |
Ограничения
При использовании горизонтального шардинга есть ряд ограничений.
Свежие записи
В случае разделения таблицы на разные сервера, по ней невозможно сделать общую выборку. Например, нельзя получить список последних десяти фотографий или новостей из примеров выше. Если это необходимо, следует использовать дополнительную таблицу, которая будет содержать только 10 последних фоток (или новостей). Вставлять туда данные нужно будет при каждом добавлении фотки:
(Сохраняем ID новых фоток в отдельную таблицу на одном (основном) сервере)
1 | <? |
Чтобы эта таблица не стала очень большой ее следует постоянно очищать. Например, оставлять только последних 100 записей:
(Второй запрос будет постоянно удалять все записи дальше 100-й)
1 | <? |
Поиск и фильтрация
Поиск и фильтрацию по данным таблицы необходимо проводить с помощью подходящей технологии, такой как Elastic Search. Индексация данных в таком случае будет происходить сразу на всех шардах таблицы.
Кроме этого, можно использовать подготовку данных для поиска заранее для каждой возможной выборки. Например, мы реализовать поиск фотографий разных размеров. Тогда, необходимо определить заранее группы возможных размеров фотографий:
- big
- medium
- small
Для каждого размера можно создать отдельную таблицу, которая будет хранить ID и другие необходимые данные фотки. При вставке фотки в эти таблицы будут попадать соответствующие ID:
(Сохраняем ID новых фоток в отдельную таблицу на одном (основном) сервере)
1 | <? |
Далее мы сможем очень просто сделать выборку всех фоток нужным размером:
(выбираем нужную таблицу для поиска по заданным критериям)
1 | <? |
Перебалансировка
При добавлении новых шардов необходимо производить перебалансировку данных. Так, если шардов было 2, а стало 3, некоторые записи должны быть перемещены на новый шард.
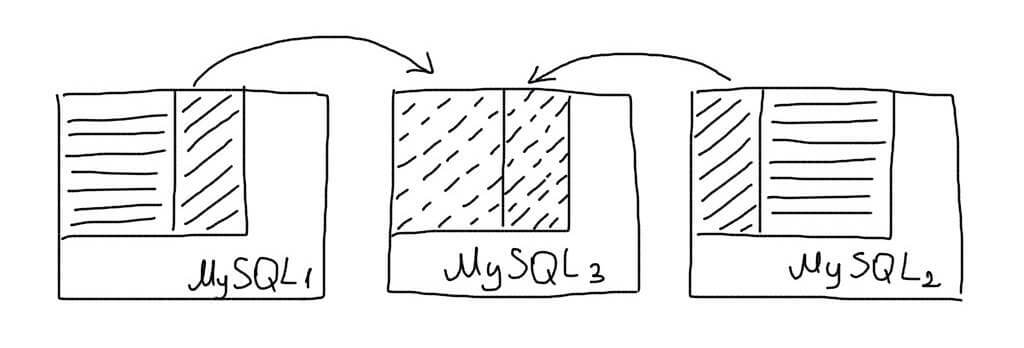
Для того, чтобы перебалансировать данные в работающем приложении, необходимо использовать два набора шардов — старый и новый. Для каждой записи необходимо хранить статус ее распределения — произошла ли перебалансировка или нет. В момент выборки данных мы будем проверять этот статус. Если данные еще не перемещены, мы будем перемещать их и ставить отметку в статус. Статус удобно хранить в key-value базе данных либо в отдельной таблице. Для примера с фотками пользователей:
(производим перебалансировку прямо во время выборки)
1 | <? |
Отказоустойчивость
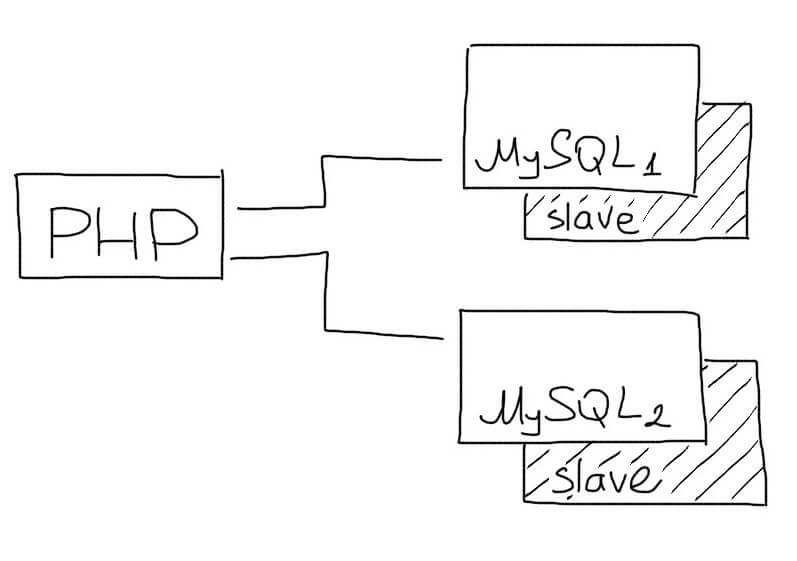
При увеличении количества шардов растет вероятность выхода из строя одного из них. Для обеспечения отказоустойчивости каждый шард необходимо резервировать с помощью Master-Slave репликации.
Партиционирование
MySQL также поддерживают партиционирование. Это возможность разделить таблицу на разные логические группы в рамках одного сервера. Партиционирование позволяет улучшить эффективность работы с большими таблицами, когда большинство операций производится только со свежими данными (т.е. в “верхушке” таблицы). Этот подход работает только в рамках одного сервера.
Самое важное
Горизонтальный шардинг — одно из самых мощных средств масштабирования базы данных. Разделение таблицы на отдельные сервера позволяет масштабировать их практически бесконечно. Внедряйте шардинг постепенно и начинайте только с самых больших таблиц. Используйте вертикальный шардинг для распределения нагрузки между группами таблиц.